
98% of FinOps teams now manage AI spend, but most can't explain what's driving it. Here's what token-level visibility requires, and why building it now is a competitive advantage.
Key points:
- 98% of FinOps teams now manage AI spend, but most cannot explain what is driving it.
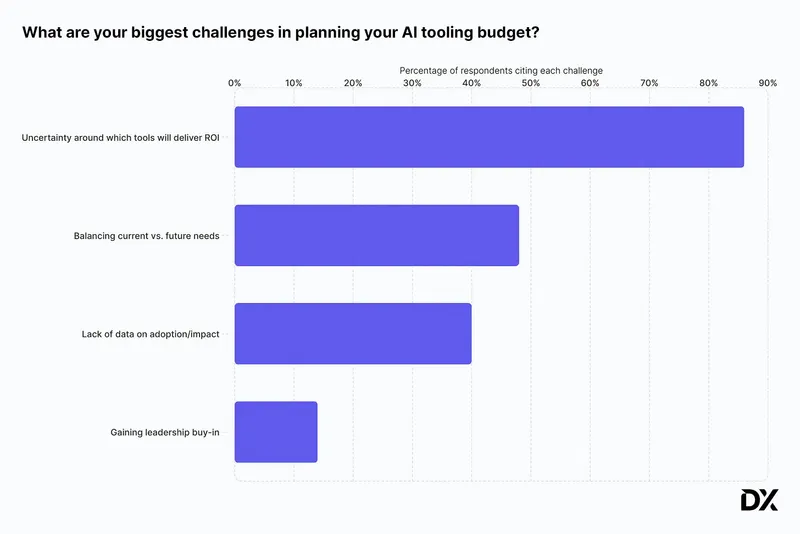
- 86% of engineering budget holders are uncertain which AI tools are delivering the most benefit.
- Cost baselines built today become the benchmarks for AI ROI, negotiations, and investment decisions.
Two years ago, 31% of FinOps teams managed AI spend. According to the FinOps Foundation's State of FinOps 2026 report, that number is now 98% (read our commentary on the report here). That velocity is both remarkable and somewhat alarming, creating unprecedented new challenges for FinOps practitioners. Responsibility for AI cost management has expanded, yet the tooling required to govern those costs at a decision-making level has not kept pace.
"The rapid adoption of generative AI drastically outpaced the evolution of native cloud billing tools," says Rajeev Laungani, Head of Product at Virtasant. "Most organizations are still relying on estimates rather than precise, unified, metric-based data." The result is an industry still in the “wild west” phase of AI FinOps, flying partially blind on a rapidly accelerating cost category.
It follows that the top tooling request in The State of FinOps 2026 report is granular monitoring of AI spend at the token, LLM request, and GPU utilization level. Tools that would definitively answer the question most boards and executives are asking: “Which of our AI features are actually returning more value than the compute they consume?” This opacity creates AI spend that is functionally unforecastable, accountability that is impossible to assign, and ROI conversations that are abstractions at best.
But while the commercial tooling market has not yet solved this, this moment in the evolution of FinOps marks a new opportunity. Organizations that build internal token-tracking infrastructure now, via open-source methods or otherwise, will own the cost baselines that define competitive AI economics for the next several years.
Why AI Spend Is Harder to Govern Than Cloud Spend
Traditional cloud costs have a logic to them. A virtual machine runs for an hour and produces a predictable, discrete charge. Budgets are built around that predictability, and when something is off, the variance is explainable. But AI costs work on entirely different terms.
Token pricing looks negligible at the individual call level, often fractions of a cent. But across dozens of enterprise workflows running continuously, those fractions compound. The Zylo 2026 SaaS Management Index found that AI-native spending nearly doubled in 2025, driven in part by AI add-ons and consumption-based pricing that inflates costs mid-contract across SaaS, public cloud, and private infrastructure. None of those billing streams produces a unified view by default.

The cross-cutting nature of AI spend is what makes it particularly difficult to govern, and FinOps practitioners are developing best practices for applying AI to FinOps and FinOps to AI, in real-time. Unlike cloud infrastructure, which typically sits in defined accounts tied to specific teams, AI costs surface simultaneously across SaaS subscriptions, public cloud API calls, and increasingly, private GPU infrastructure. A single AI feature might generate charges across three separate vendor invoices.
"Without a central gateway to track model usage, calculate ROI, and monitor token economics before requests reach the provider, cost management is just retroactive guesswork based on monthly invoices."
—Rajeev Laungani, Head of Product, Virtasant
Three distinct billing categories now exist for enterprise AI workloads:
- Token-based API calls billed by input and output volume
- Reserved or on-demand GPU compute
- AI-enabled SaaS seats priced by tier or usage
Each is priced differently, governed differently, and without instrumentation at the point of execution, none of them produce the data required to answer the questions a CFO or CIO actually needs answered.
IDC's FutureScape 2026 put a number to the risk: by 2027, G1000 organizations will face up to a 30% rise in underestimated AI infrastructure costs, not from reckless spending, but from under-forecasting and missing expenses unique to AI-specific workloads.
Where Commercial Tooling Falls Short
FinOps platforms have begun adding AI cost modules, and most of them are useful as far as they go. The problem is where they stop. Commercial tooling today predominantly operates at the billing level: monthly provider-level allocation, high-level usage summaries, and cost-by-account reporting. That data answers questions that finance needs for historical reporting, but doesn't answer the questions needed to make forward-looking decisions.
Billing-level data tells you that AI spend spiked in a given month; it doesn't tell you which pipeline stage triggered it, which team owns the workflow, or whether the feature driving the cost is generating any measurable return. Without per-request attribution tagged to a team, feature, or business unit, no one can be held accountable for an anomaly, and no one can make a credible claim about ROI.
"Simply looking at the total monthly bill from your provider is a reactive measure. It tells you that you overspent, but not why."
—Nir Gazit, Co-Founder and CEO, Traceloop
The State of FinOps 2026 report captures the same frustration from practitioners inside enterprise organizations. Pre-deployment architecture costing emerged as a top desired tooling capability. Teams want to model AI costs before infrastructure commitments are made, not after invoices arrive. As one practitioner framed the maturity gap: "Dashboards are table stakes of yesterday — reactive. You have to move to proactive, real-time, automation."
FinOps practitioners should understand, however, that the only path forward isn’t building an entirely custom solution from scratch. Open-source LLM gateways, lightweight proxy layers, and observability frameworks built on standards like OpenTelemetry offer practical starting points that layer on top of existing infrastructure. It comes down to which instrumentation layer fits the organization's current architecture and gets attribution data flowing now.
What Token-Level Governance Requires
Three layers of infrastructure need to work together to get AI governance right:
- Attribution infrastructure is the foundation. Every LLM call must carry identifiers for team, feature, workflow, and business unit at the point of execution. Without this tagging, cost data cannot be allocated. The core technical mechanism, as explained by Traceloop, an LLM monitoring platform, involves attaching metadata to every API request at runtime. This can be implemented through a proxy layer or an OpenTelemetry-based observability framework, neither of which requires rebuilding the existing AI stack. The organizations doing this well are typically starting with a handful of high-cost workflows and working outward from there.
- Real-time monitoring is the second requirement. Token consumption needs to surface continuously, not at billing close. A runaway agent or a misconfigured context window can exhaust a meaningful portion of a team's daily budget before any invoice flags the anomaly. Routing model traffic through a unified gateway creates the instrumentation layer that makes this possible. Several open-source options, including LiteLLM and PortKey, exist specifically for this purpose and can be adopted without commissioning custom infrastructure from the ground up.
- GPU utilization visibility is crucial for any organization running models on owned or reserved infrastructure. The economics of self-hosting only hold when GPU utilization is high enough to justify the fixed cost. Idle GPU hours erase the case for self-hosting quickly, but without visibility into actual utilization alongside token volume, the decision to self-host versus use managed APIs cannot be made on evidence.
Token Attribution Is a Unit Economics Problem, Not Just a Cost Problem
For CFOs and CIOs evaluating AI investment strategy, granular token attribution answers the question most enterprises cannot answer today: are AI features profitable relative to compute?
A 2026 survey of engineering budget holders found that 86% feel uncertain about which AI tools are providing the most benefit. But gaining clarity is a data problem before anything else. Without per-request attribution, there is no cost-per-workflow. Without cost-per-workflow, there is no return-on-workflow.
Model selection is another dimension of the same problem, one that’s increasingly within the FinOps mandate. Here, FinOps plays a complementary role. While determining which model to use is an engineering decision, FinOps frameworks surface the cost-to-performance trade-offs so engineering can make a decision from evidence. The cost difference between models can be substantial at scale, and without per-request attribution, inefficiencies are invisible.
"Routing simple classification tasks to a massive, expensive model instead of a cheaper, fine-tuned one destroys your gross margins."
—Rajeev Laungani, Head of Product, Virtasant
Unit economics, AI value quantification, and influencing technology selection decisions are now distinguishing characteristics of high-performing FinOps teams. Many organizations are being asked to self-fund AI investments through cloud optimization savings; according to Laungani, some are going further than that. "We're starting to see customers hold back cost optimizations knowing that they're going to need to use the ROI from that to invest in AI," he says.
The cost baseline for each AI initiative is not just a governance tool, but a strategic asset. Enterprises with usage data at the token and model level can benchmark provider pricing, evaluate model substitution, and make build-versus-buy decisions from evidence. Those without that data are making the same decisions from intuition, and unsuccessfully defending them to boards that are asking for proof.
The technical implementation, however, is only half the problem. "The organizational elements are actually much harder to solve than the technical ones," says Laungani. Getting engineers to prioritize token efficiency when they are heavily incentivized to ship AI features quickly is a significant cultural hurdle.
FinOps practitioners are most effective here not as decision-makers on what to tag or who owns the data, but as facilitators, the function that gets product, engineering, and finance into the same room to agree on a shared allocation taxonomy. "Tooling is useless unless you have established pre-agreed organizational accountability for when those baseline token budgets are exceeded," Laungani stresses.
What to Do Before the Tools Catch Up
The commercial tooling gap won't close overnight, and waiting for vendors to solve it is not a strong strategy as AI spend continues to compound.
But there are three practical starting points that don't require a platform replacement or a major engineering initiative:
- Implement a tagging and metadata strategy for all LLM calls now. Every API request should carry identifiers for team, feature, and business unit at the point of execution. This single step is what makes everything else (anomaly detection, accountability, ROI calculation) possible.
- Route model traffic through a unified gateway or proxy to create a continuous instrumentation layer. Open-source options make this accessible without a ground-up custom build.
- Establish a cost-per-workflow baseline before AI spend grows further. Even rough baselines built today become the benchmarks against which future spend is evaluated, future negotiations are anchored, and future ROI claims are validated or challenged.
The organizations setting these baselines now are building the measurement infrastructure that will let them prove AI value to the board and scale confidently in the direction of what's working.
What is FinOps for AI?
FinOps for AI applies cloud financial management principles to AI workloads, including token consumption, LLM API calls, and GPU infrastructure. As AI spend has grown, FinOps teams have become the default owners of AI cost governance, though the tooling required to manage it at a granular level is still catching up.
Why is AI spend harder to govern than cloud spend?
Cloud costs map to discrete, predictable resources. AI costs are dynamic and cross-cutting, surfacing simultaneously across SaaS subscriptions, API calls, and GPU infrastructure. Token pricing looks negligible per call, but compounds rapidly at scale, and no single billing stream produces a unified view by default.
What does token-level visibility actually mean?
Token-level visibility means attributing every LLM call to the team, feature, workflow, or business unit that generated it at the point of execution. Without that attribution, cost data cannot be allocated, anomalies cannot be explained, and ROI cannot be calculated at the feature level.
Do FinOps practitioners need to build a custom solution to get token-level attribution?
Not necessarily. Open-source LLM gateways like LiteLLM and PortKey, and observability frameworks built on OpenTelemetry, offer practical starting points that layer on top of existing infrastructure. The goal is getting instrumentation in place now, not replacing your entire stack.
Why does token attribution matter for ROI, not just cost reduction?
Without per-request attribution, there is no cost-per-workflow. Without cost-per-workflow, there is no return-on-workflow. Token attribution is the data layer that lets enterprises answer whether a specific AI feature is profitable relative to the compute it consumes (the question boards and executives are increasingly asking).









.svg)



